
12 Sampling Distributions
12.1 The Goal, and Fundamental Dilemma, of Statistics
Recall that the goal of statistics, at the most basic of levels, is to draw conclusions regarding the parameter values in a population of interest by analyzing a sample and computing statistics. Revisit Figure 10.1 for a visual representation of this procedure. In Chapter 11 we discussed in depth the study of descriptive statistics. Descriptive statistics aim to describe the data that have been observed through the study, through the computation of sample statistics or similar graphical procedures. That is, using the techniques from descriptive statistics we can take a sample and derive statistics from it. The fundamental dilemma we are faced with, however, is that a statistic will not typically equal a parameter value exactly. That is, the value we compute using a sample for any property1 will not equal the value that the same property would take on in the population. As a result, while descriptive statistics allow us to understand thoroughly the data that we have collected, they do not (alone) address the complete goal of statistics.
To complement descriptive statistics we wish to be able to make statements about how sample statistics relate to, or are connected to, parameter values. In order to do so it is worth asking “why do the values of statistics tend to differ from the values of the corresponding parameters?”. Intuitively, the issue we are faced with is that a sample does not include every element of the population. As a result, quantities computed on a sample will differ from the same quantities computed in the population owing to the different make-up of the sample. We could envision what would happen if we took a second, different sample from the same population. We would likely get different elements in the sample, and as a result, anything computed on the sample would differ from the first time. If we continued to take samples, compute the values, and compare them we would find that each sample is subtly different from every other, leading to the values of statistics moving around sample-to-sample. Of course, if we could access the full population, the value of the parameter would never change since there is only one, true value. These differences sample-to-sample are referred to as sampling variability, and explain the core reason why statistics and parameters differ from one another.
Definition 12.1 (Sampling Variability) Sampling variability refers to the variation that occurs between samples drawn from the same population (whether the same method for selection is used or not). This variability manifests itself in the values of statistics that are computed on a sample, where repeated sampling from the same population will result in different values for the statistics. This variability is inherent in the sampling process and emerges owing to the fact that each sample will consist of different elements from the same population.
To understand this procedure completely, consider the following population of squares, depicted visually. If we had access to this entire population we would be able to determine any parameter value that we would like to know about, for instance, understanding the proportion of black squares present (in the population this results in a proportion of 0.195).
Generally, we will be unable to observe an entire population, and instead would be required to take random samples. If we take samples of size \(10\) from the population we may end up with something like the following.

This sample, however, was not the only sample that we could have seen. Consider the following \(16\) samples. In each of them the number of black squares (and thus the proportion of black squares) differs. These differences arise naturally based on which squares happened to be included in the sample, and those that happened to be ignored. If we continued to sample more and more from the population and work out the corresponding proportion of black squares observed, we would see the proportions continue to vary.

Owing to sampling variability, every time that we take a sample we expect to get a different value for our statistic. Because of this we can often regard the value of the statistic as being random. Ultimately, if the members of our sample determine the value of our statistic, and the members of our sample are randomly selected, then we know that the value of our statistic is a random value. Any numeric quantity which takes on random values is referred to as a random variable (Definition 5.1) and as a result statistics are random variables. Because statistics are random variables we must also conclude that statistics have distributions. The distribution of a statistic is referred to as the sampling distribution for the statistic, and serves as the primary tool for understanding how well the values of statistics and parameters agree with one another.
Example 12.1 (Sadie, Charles, and Ketchup) Sadie and Charles get along quite well in most regards, however, they cannot agree at all on ketchup. Specifically, Charles finds ketchup to be repugnant, disliking even being in its presence. Sadie, on the other hand, finds it to be quite pleasant and will happily enjoy it alongside many dishes. This is a frequent point of contention for them. As a result, they decide that they should take a survey of the individuals at their favourite coffee shop to settle the debate once-and-for-all. Thus, they go around asking each individual their thoughts on ketchup.
- In the population as a whole, the number of people who like ketchup is best described by what distribution? What is the parameter of interest for Charles and Sadie?
- If it is found that more people in the coffee shop agree with Charles than with Sadie, does that mean that more people in the population dislike ketchup? Explain.
12.2 Sampling Distributions
Definition 12.2 (Sampling Distribution) A sampling distribution is the distribution of a sample statistic. The sampling distribution arises due to sampling variability, rendering samples – and statistics computed using samples – random.
The fact that statistics are random variables is the critical realization that facilitates inferential statistics. However, this is a concept which is not always immediately clear. It is worth reemphasizing how sampling distributions emerge, and how they differ from both frequency (or data) distributions, and from the underlying population distributions. We first consider a population. In this population the trait of interest will differ between individuals, and these differences will be summarized by a relevant parameter. When populations are large2 we can view the trait in the population as being randomly distributed. We are thinking that, if we were to observe a single individual from the population, their value of the trait would follow some distribution. We call this underlying distribution the population distribution. Our interest is ultimately in the population distribution.
We can then think of taking a random, finite sample from the population. We can measure the value of the trait for all individuals in the sample. These observations constitute an observable dataset. Within these data we can discuss the frequency distribution or the data distribution, which summarizes how often values of the trait occurred in the sample. The data distribution describes what we actually observed, and we can characterize it exactly. We hope that our sample was a good sample3 and as a result, we hope that the data distribution is similar to the population distribution. However, we do not expect that these distributions will coincide directly since our sample is a subset of the population, meaning many values have been excluded. Using this sample we are able to compute statistics that are the sample version of the parameters of interest. These statistics characterize the data distribution in a similar way to the parameters characterize the population distribution.
We can then imagine repeating this process of sampling many times. Each time we do we would receive a slightly different sample, which in turn produces a slightly different data distribution, and as a result a slightly different statistic value. Suppose that we recorded the value of the statistic each time that we took our sample, and then re-sampled again. Doing this over and over again would produce a set of values for the statistics. These values would be seen as specific realizations from the distribution of possible realizations of the sample. This distribution is the sampling distribution. The sampling distribution characterizes the random variability in the value of a sample statistic, had we been able to repeatedly compute this over many different samples. The more spread that is in the sampling distribution, the more we expect different samples to differ from one another in terms of the value of the relevant statistic.
Consider the previous example of sampling squares from the population in Figure 12.1. If we continued to do this over, and over again, and we recorded the proportion of squares that were black, the resulting distribution would be the sampling distribution of the proportion of black squares. Looking at this distribution we could then ask “given a single sample from the population, how likely are we to get a representative value for the sample proportion?” If this probability is high then we can be relatively confident that a sample will provide us with a useful guess to the true parameter value. If this probability is low, we cannot be sure that we are learning much from the sample.
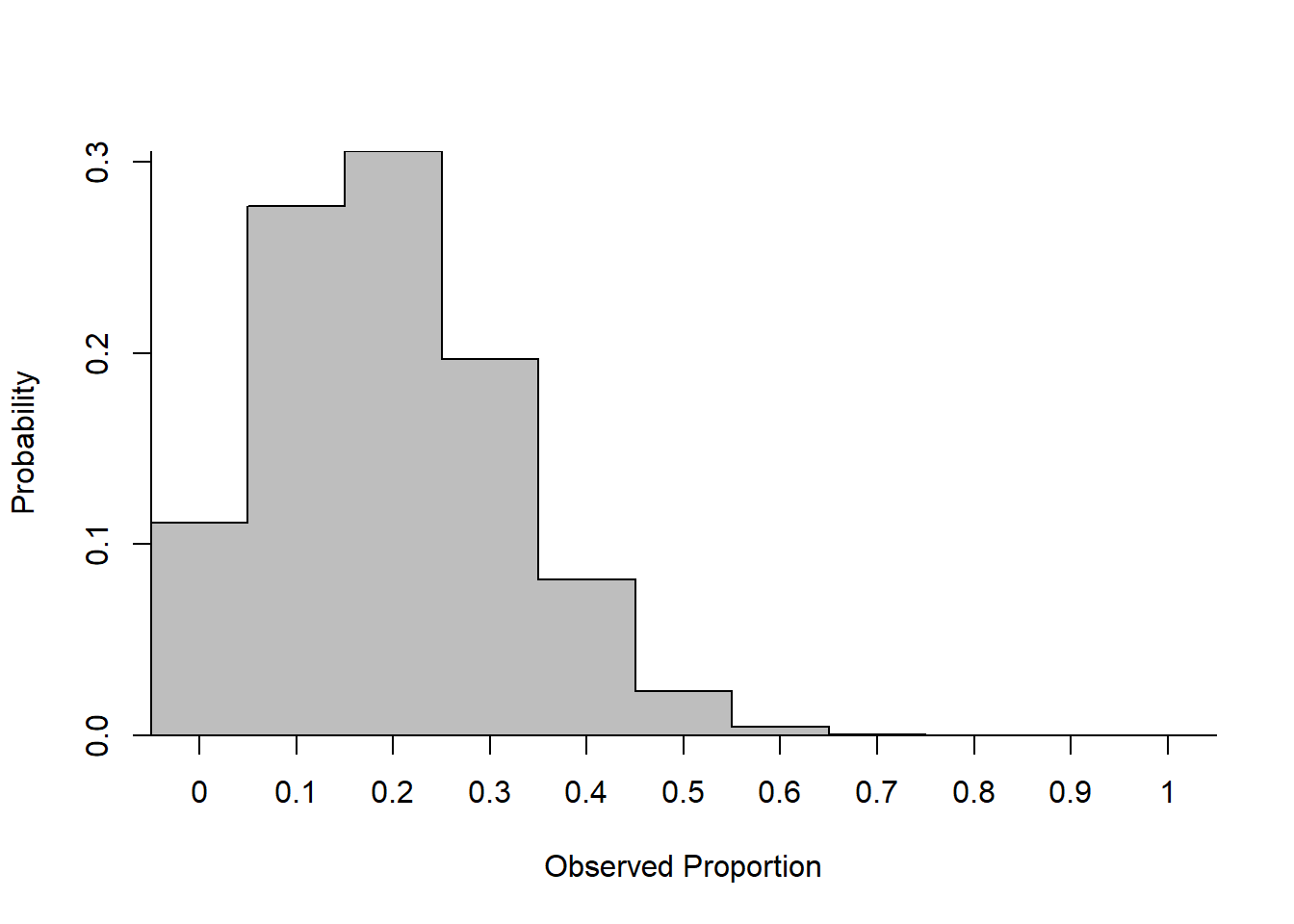
If the sampling distribution of a statistic were known exactly, then probabilities could be computed regarding that statistic in the same way as probabilities are computed for any random variable. In our example, for instance, if we took \(\rho\) to represent the sample proportion for a random sample of size \(10\), then we could claim that \[P(\rho = 0.2) \approx 0.3056561.\] Because we know the value of the population parameter, and because \(0.2\) is as close to \(0.195\) as a sample can get in a population of size \(10\), we can thus say that nearly \(31\%\) of samples will provide an estimate that is as close to the truth as is possible, given the sample size. If we instead consider \[P(0.1 \leq \rho \leq 0.3) \approx 0.7792981,\] and so nearly \(78\%\) of our samples should be within \(1\) of the closest sample value to the true population parameter. That is, we can use the sampling distribution to assess how reliable our statistic is as a proxy for the parameter value.
A major difficulty in the application of this procedure in practice is that typically we do not have the true population on hand to either directly compute the sampling distribution, or to know what the true parameter value should be. If we did have access to the full population we would not need to use samples in the first place. Despite these limitations, the sampling distribution is still the key tool in unlocking an assessment of reliability of statistics as proxies for parameters. By recognizing that the sampling distribution is inherently useful in explaining the random behaviour of statistics, all that remains is being able to connect the sampling distribution to the population distribution. Fortunately, we will often find that, even without knowing the specific sampling distribution, we can make definitive statements about the link between the sampling distribution and the population distribution, giving a bridge between statistics and the corresponding parameters.
Example 12.2 (Sadie, Charles, and Ketchup (Repeated Over and Over)) After recognizing the lack of scientific validity of their single sample, Charles and Sadie decide that they should repeat their survey many times over. Each time they gather a sample of individuals and ask whether they agree with Charles or Sadie more. They do this many, many times, and report the proportion of individuals who agree with Sadie in the following chart.
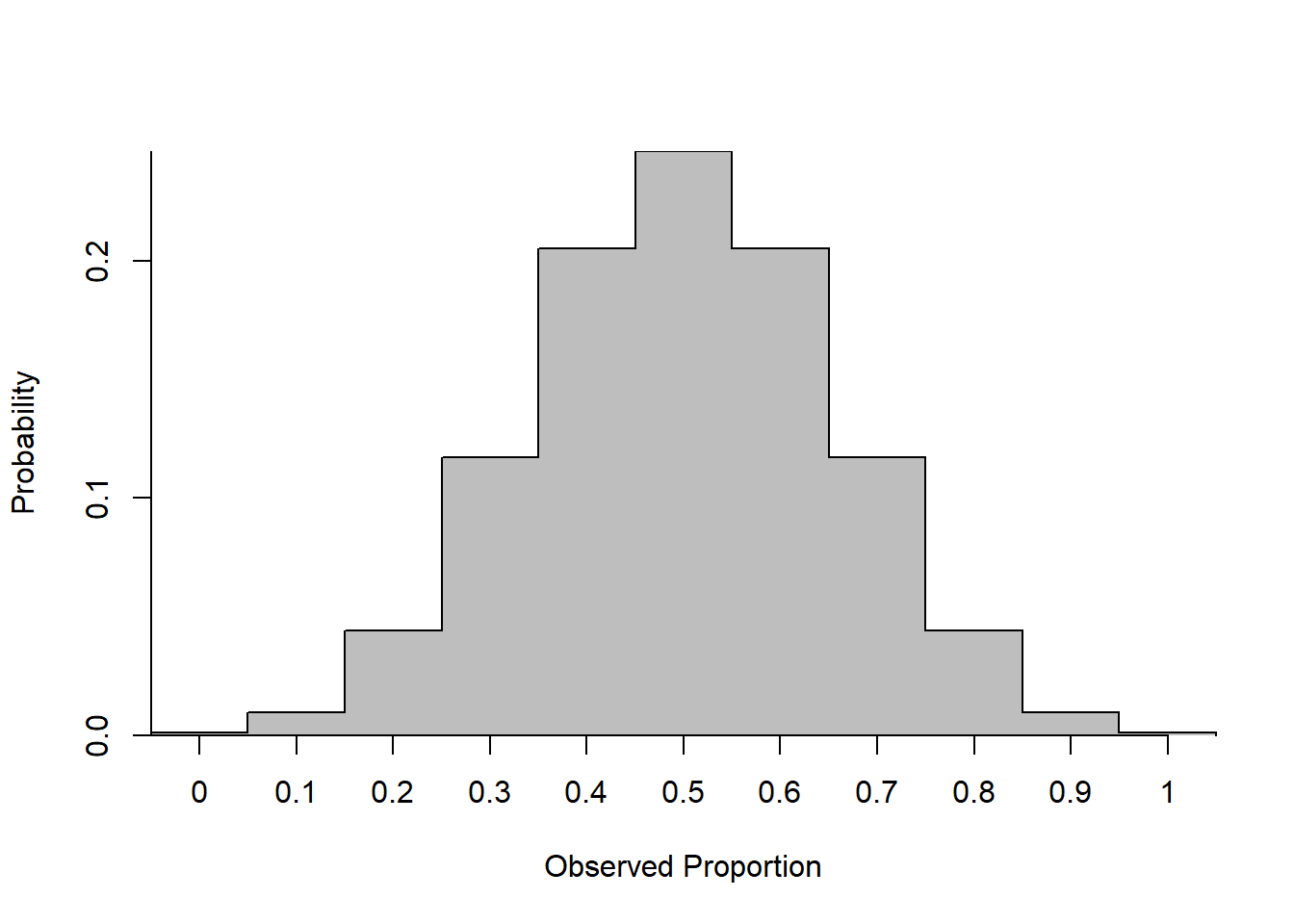
- How is this graph related to the data distribution? The population distribution? The sampling distribution?
- According to this graph, what is (approximately) the probability that in a sample they will find more people agreeing with Sadie?
- What conclusions can be drawn?
12.3 The Sampling Distribution of a Sample Mean
As an illustrative example demonstrating the connection between the sampling distribution and the population distribution we will consider the case of sample means. Note that sample means are among the most important statistics that are worked with and so this example is representative of a large quantity of statistics in practical use. Moreover, statistics like sample proportions can be thought of as the sample mean of binary data.4 Other statistics can be analyzed in a similar manner, allowing us to draw similar conclusions for other parameters of interest.
12.3.1 Characterizing the Sampling Distribution of the Sample Mean
Consider an arbitrary population distribution for some trait. Suppose that \(X\) is a random variable that is drawn from this population distribution, so that the mean in the population is \(E[X]\) and the variance in the population is \(\text{var}(X)\). We will typically denote \(E[X] = \mu\) and \(\text{var}(X) = \sigma^2\), as we did for normal populations. Now, if we consider drawing a sample of size \(n\) from this population, and if we suppose that these are drawn independently of one another, then our sample can be thought of as a collection of \(n\) independent and identically distributed (Definition 5.12) random variables, denoted \(X_1, X_2, \dots, X_n\). Each of these random variables will have mean \(\mu\) and variance \(\sigma^2\), and each is independent of all the others. Then, the sample mean of this hypothetical sample is given by \[\overline{X} = \frac{1}{n}\sum_{i=1}^n X_i.\] Note that we are using the same notation we used for random variables where capital letters indicate a random quantity, and the corresponding lowercase letters represent a specific value. Thus, \(\overline{X}\) is thought of as a random variable which represents the sample mean for a random sample. If we actually take a sample and compute the mean, we would have a corresponding \(\overline{x}\), which is just one realization of the random variable \(\overline{X}\).
Since \(\overline{X}\) is random it has a distribution. Because it is a statistic, its distribution is a sampling distribution, and in particular it is the sampling distribution of the sample mean. The specific form of this distribution will not generally be known, however, we can ask questions regarding parameters of this distribution (that is, sampling distribution parameters). Specifically, we may ask ourselves whether it is possible to determine \(E[\overline{X}]\) and \(\text{var}(\overline{X})\). Note that these are not the same as \(E[X]\) and \(\text{var}(X)\), where the former are the parameters of the sampling distribution and the latter are the parameters of the population distribution.
Practically this means that the sample mean is centered on the true population mean, and on average should be correct. Moreover, the variance of the sample mean is related to the variance in the population5 and is inversely related to the sample size. The relationship to the sample size gives a mathematical justification for the intuition that “larger samples are preferable.” It makes sense that if your sample size is larger, you will get a better estimate of the truth. This can be justified since, as the sample size grows, the variance of the sampling distribution shrinks, and the sampling distribution becomes more heavily concentrated around the true population mean. It is constructive to consider what happens to the variability in the sampling distribution as the sample size increases \(n\to\infty\).
Specifically, as the sample size grows more and more, the variance shrinks smaller and smaller. Eventually, in the limit, the variance will shrink all the way to \(0\). At this point, we will be left with a sample mean that is exactly equal to the population mean, since \(E[X] = E[\overline{X}]\) and the variance of \(\overline{X}\) is zero. Of course, if we could take an infinite sample we would have taken every member of the population into the sample, and so we should expect that the two align in that case. Now, it will never be the case that we have a truly infinite sample, and so there will always be some variability that remains in the sampling distribution. However, the reduction in variance occurs even at finite samples. As more and more members are included in the sample, there is less and less variability in the statistic, and the results become more and more concentrated around the true population value. The important point of this characterization is that it does not matter what the population distribution is, nor what the value for the sample mean is.
More often than not when discussing the variability of the sampling distribution the measure of choice will be the standard deviation rather than the variance. That is, instead of reporting that \(\text{var}(\overline{X}) = \dfrac{\sigma^2}{n}\), it is far more common to report that \(\text{SD}(\overline{X}) = \dfrac{\sigma}{\sqrt{n}}\). These two quantities hold the same information, and it is straightforward to move from one to the other by either taking the square root or squaring the quantity. Now, when the standard deviation is computed for a statistic, such as the sample mean, it is not typically referred to as a standard deviation. Instead, it is called a standard error.
Definition 12.3 (Standard Error (of a statistic)) For any statistic \(\widehat{\theta}\) the standard error of the statistic is given by its standard deviation. That is, \[\text{SE}(\widehat{\theta}) = \text{SD}(\widehat{\theta}).\]
Definition 12.4 (Standard Error (of the Sample Mean)) The standard error of the sample mean (SEM) is the standard error of \(\overline{X}\). For a population with variance \(\sigma^2\), this is given by \[\text{SE}(\overline{X}) = \frac{\sigma}{\sqrt{n}}.\]
The standard error is a useful metric since, if reported alongside the estimate, we can directly quantify the uncertainty of the statistic. A higher standard error equates directly to more uncertainty in the statistic and this uncertainty is measured on the same scale as the statistic itself. Now, in practice, you will not have an exact value for the standard error since it relies on knowledge of \(\sigma\). Still, it will often be the case that we can get a good sense as to the standard error via the sample standard deviation, and use this quantity in place.6
Example 12.3 (Charles and Sadie Visit the Zoo) One day Charles and Sadie decide to visit the local zoo (a zoo with a strong focus on conservation research). Charles and Sadie learn that:
- Eastern lowland gorillas weigh on average around \(407\)lbs, with a standard deviation of approximately \(65\)lbs.
- Sumatran elephants weigh on average around \(6600\)lbs, with a standard deviation of approximately \(750\)lbs.
- Leatherback sea turtles weigh on average around \(1036\)lbs, with a standard deviation of approximately \(125\)lbs.
Charles and Sadie think about finding samples of \(16\) of each of these species in the wild.
- Characterize the sampling distribution for each of the species.
- If larger samples were taken, how would this change the mean and standard error of the sampling distributions?
- Suppose a sample of size \(n\) is taken of leatherback turtles. How large of a sample of Sumatran elephants would be needed to have the same standard error of the sample mean?
12.3.2 The Sampling Distribution of the Sample Mean in Normal Populations
While it is possible to make concrete statements regarding the relationship between the parameters of the sampling distribution and the population distribution, we are not able to make concrete probability statements regarding the sample mean in general.7 However, in certain cases we are able to make stronger statements regarding the sampling distribution. These statements stem from knowledge that we may have of the underlying population. While it may be unrealistic to make strong assumptions regarding the values of population parameters, it is often the case that we may have a general idea of the shape of the underlying distribution. In Chapter 8 and in Chapter 9 we discussed how certain named distributions emerge as a result of the underlying processes, and how these can be identified based on the particulars of a given scenario. If you are in a case where you are willing to make an assumption regarding the shape of the population distribution, it may be possible to make stronger statements regarding the sampling distribution.
The most common assumption to make regarding an underlying population distribution is that the population is (approximately) normally distributed. That is, we assume that \(X \sim N(\mu,\sigma^2)\), where we perhaps have no knowledge as to what the values of \(\mu\) or \(\sigma^2\) are. Making this assumption regarding the shape of the distribution allows us to fully characterize the sampling distribution of \(\overline{X}\). To do so, we need only revisit the closure properties of the normal distribution. Specifically, if we have multiple quantities which are independent of one another, and each of them follows a normal distribution, then the sum of these random quantities will also follow a normal distribution. In addition, if we have a normally distributed random variable, and we multiply it by a constant, then the result will still be a normally distributed random variable.
The sample mean is constructed by first taking a sum of a set of random variables, and then second multiplying this summation by \(\dfrac{1}{n}\). If the population is normally distributed then this is the sum of a set of normally distributed random variables, and as a result, will be normally distributed itself. That is, whenever the population distribution is normally distributed, the sampling distribution of the sample mean will also be normally distributed.
In these cases, it is possible to make more concrete statements regarding the behaviour of the sample mean. For instance, an application of the empirical rule tells us that in approximately \(95\%\) of cases, the sample mean will be within two standard errors of the true mean. Supposing that the population variance is not too large, or the sample size is sufficiently large, this gives reasonable certainty that the sample mean is a good proxy for the population mean. Using this result to make definitive probability statements still requires knowledge of \(\sigma^2\) in the population, which will often be an unrealistic assumption. In the coming chapters we will learn how to overcome this shortcoming and quantify the uncertainty in the values of statistics even without direct knowledge of the population variance. A more pressing question, however, is whether there are any strong statements that can be made about the distribution of the sample mean when the population is not normally distributed.
Example 12.4 (Charles and Sadie Consider their Zoo Trip) After returning from the zoo, Charles and Sadie wish to figure out whether the zoo appeared to have a good representation of the animals or not. They record all of the following information:
- Eastern lowland gorillas weigh on average around \(407\)lbs, with a standard deviation of approximately \(65\)lbs. The zoo had \(4\) gorillas with an average weight of \(342\)lbs.
- Sumatran elephants weigh on average around \(6600\)lbs, with a standard deviation of approximately \(750\)lbs. The zoo had \(25\) elephants with an average weight of \(6750\)lbs.
- Leatherback sea turtles weigh on average around \(1036\)lbs, with a standard deviation of approximately \(125\)lbs. The zoo had \(64\) turtles, with an average weight of \(1030\)lbs.
In order to proceed, Charles and Sadie are willing to assume that the animals all have weights that are approximately normally distributed in the population.
- Describe the sampling distributions for each animal from the zoo.
- If the sample of gorillas is randomly selected from the wild, what is the probability that the zoo would have a sample weight as low (or lower) as what they have?
- If the sample of elephants is randomly selected from the wild, what is the probability that the zoo would have a sample weight as high (or higher) as what they have?
- If the sample of turtles is randomly selected from the wild, what is the probability that the zoo would have a sample weight between \(1020.375\) and \(1051.625\)?
12.3.3 The Central Limit Theorem
If the underlying population does not follow a normal distribution it will not be the case that the sampling distribution is exactly normally distributed. However, a remarkable result states that, while we cannot state that a normal distribution will be exactly correct for the sampling distribution, we can state that, in large enough samples, the normal distribution will be approximately correct for the sampling distribution. That is to say, no matter the population distribution, if the sample size is large enough, the sample mean will have a distribution that is approximately normal. This statement is known as the Central Limit Theorem, and it sits at the heart of many of the results we will leverage for inferential statistics.
The power of this result is difficult to overstate. Simply put, if \(n\) is sufficiently large then we do not need to know anything about the underlying population distribution in order to make use of the results from the normal distribution in assessing its behaviour. No matter the underlying population we can calculate using normal probabilities, make use of the empirical rule, and make definitive statements like those in the previous section. Importantly, these probabilities will not be exactly correct, however, even for moderate large \(n\), they will likely be close enough to be very useful. A natural question regarding the application of the Central Limit Theorem is then how large does \(n\) have to be? The short answer is that it depends. The required sample size for \(n\) depends primarily on how close to normality the original population is. If you have a population that is approximately normal to begin, even very small sample sizes will suffice for approximate normality. If the original population is further from normality then it will take larger samples to apply the CLT.
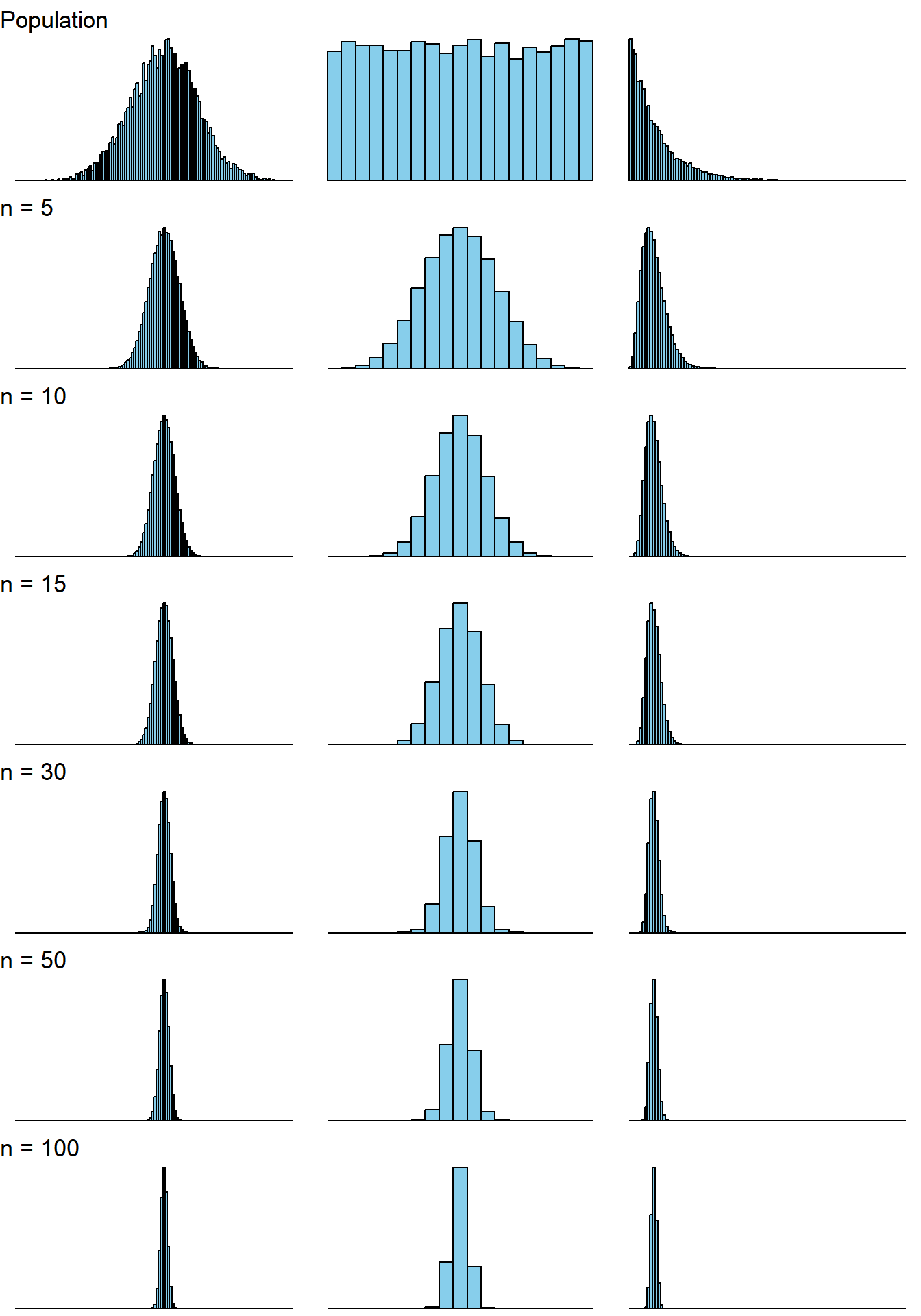
Often, the concrete advice will be that, if \(n \geq 30\), the CLT will apply. As with most hard-and-fast rules, I would advise against following this dogmatically. The issue is two-fold. First, if populations are near to normality then the CLT will likely provide a suitable approximation for much smaller \(n\) than \(30\). Second, and more concerning, if the initial population is sufficiently far from normality it may require substantially larger sample sizes for the sampling distribution to appear normal. Instead of using a definitive, arbitrary cutoff, it is more sensible to consider the problem at hand, the likely shape of the population, and the sensitivity of your conclusions to the assumption that the CLT Is a good approximation. While it is hard to establish a clear-cut rule, it is always the case that as \(n\) increases in size the approximation becomes more and more reasonable. Throughout these course notes we will endeavour to make clear whenever the sample size is “large enough” for the CLT to hold. When in doubt, taking \(n\geq 30\) provides a useful starting point.
Example 12.5 (Charles and Sadie Re-Consider their Zoo Trip) After working out the probabilities associated with their zoo trip and the likelihood of observing what they observed (Example 12.4), Charles and Sadie do some additional research. They learn that their assumptions around the normally distributed weights of the animals likely do not hold. Instead, they learn that
- The weights of gorillas are far from normal, with different modes emerging depending on various factors around the gorilla. The zoo had a sample of size \(4\).
- The weights of elephants are close to normal, but not exactly so – there is more variability than would be expected in a normal population. The zoo had a sample of size \(25\).
- The weights of sea turtles are far from normal, exhibiting skewness and multi-modality. The zoo had a sample of size \(64\).
- Which of the conclusions that Charles and Sadie have previously drawn are still justified? Why and how?
- Which of the conclusions that Charles and Sadie have previously drawn are no longer justified? Why?
12.4 Exploring Sampling Distributions in R
The fact that the sampling distribution is best interpreted as the distribution that arises from repeatedly computing a particular statistic renders statistical programming to be an effective tool for exploring the ideas associated with sampling variability and sample statistics. If the population distribution is known, then it is possible (using the previously discussed tools for drawing samples from named distributions) to work out empirically the sampling distribution for any statistic. Moreover, we can use R to determine the necessary sample sizes in order for the sampling distribution of the sample mean to appear approximately normal. The process in all of these cases is similar: we repeatedly sample from the population distribution, compute the estimated statistic, and then record this value. Then, we can plot the sampling distribution by plotting the result of the various estimates.
The results of this first experiment demonstrate that, if the population is exponentially distributed, a sample of size \(10\) is insufficient to approximate normality. Consider what happens as you increase the sample size to the shape of the histogram. We can also see that the approximated mean and variance are close to what we would theoretically expect them to be, namely \(\dfrac{1}{4}\) and \(\dfrac{1}{160}\). If the number of replicates were increased, these values should become closer to the truth.
Perhaps more useful than considering the sampling distribution of the sample mean, however, is the use of statistical software to consider the sampling distributions of other statistics. Try to determine how you may modify this code to look at the sampling distribution for the sample variance, or the sample median, or the sample minimum, or any other statistic that can be computed on a sample. The following code will do just that for a normally distributed population.
The use of these simulations to determine the sampling distribution is an incredibly powerful tool in statistics. It allows us to work with quantities practically, even when the theory is too cumbersome to derive. What is more, the same ideas can be extended to approximate sampling distributions even when the population distribution is not known at all. The process is called bootstrapping, and it is one of the most powerful ideas that has been derived in modern statistics.
Self-Assessment
Note: the following questions are still experimental. Please contact me if you have any issues with these components. This can be if there are incorrect answers, or if there are any technical concerns. Each question currently has an ID with it, randomized for each version. If you have issues, reporting the specific ID will allow for easier checking!
For each question, you can check your answer using the checkmark button. You can cycle through variants of the question by pressing the arrow icon.
The Central Limit Theorem states that, in large samples, sampling distributions are approximately normal.
(Question ID: 0571506039)
The sampling distribution is an estimate of the population distribution.
(Question ID: 0559282069)
The sampling distribution will always be the same as the population distribution, with possibly different parameter values.
(Question ID: 0435764912)
The sampling distribution depends on the population distribution, statistic being considered, and the sample size.
(Question ID: 0413602796)
The Central Limit Theorem states that, in large samples, sampling distributions are approximately normal.
(Question ID: 0500407835)
The sampling distribution will always be the same as the population distribution, with possibly different parameter values.
(Question ID: 0985048046)
The sampling distribution depends on the population distribution, statistic being considered, and the sample size.
(Question ID: 0432839712)
The sampling distribution will always be the same as the population distribution, with possibly different parameter values.
(Question ID: 0303001117)
If a sampling distribution is known, it can be used for probability calculations relating to the values of statistics.
(Question ID: 0232227299)
The Central Limit Theorem can be used to say that, in large samples, the sampling distribution of the sample mean is approximately normal.
(Question ID: 0760767649)
The Central Limit Theorem can be used to say that, in large samples, the sampling distribution of the sample mean is approximately normal.
(Question ID: 0390300895)
The sampling distribution indicates the distribution of points in a single sample.
(Question ID: 0133364798)
The Central Limit Theorem states that, in large samples, sampling distributions are approximately normal.
(Question ID: 0572305069)
The sampling distribution depends on the population distribution, statistic being considered, and the sample size.
(Question ID: 0197524049)
The sampling distribution will always be the same as the population distribution, with possibly different parameter values.
(Question ID: 0110481828)
The standard deviation of a sampling distribution is referred to as the standard error.
(Question ID: 0344352069)
The standard deviation of a sampling distribution is referred to as the standard error.
(Question ID: 0525199498)
If a sampling distribution is known, it can be used for probability calculations relating to the values of statistics.
(Question ID: 0505507992)
If a population is normally distributed, all sampling distributions related to it will also be normal.
(Question ID: 0208677115)
The sampling distribution will always be the same as the population distribution, with possibly different parameter values.
(Question ID: 0297971631)
If a population is normally distributed, all sampling distributions related to it will also be normal.
(Question ID: 0047453828)
The sampling distribution is an estimate of the population distribution.
(Question ID: 0222888025)
The sampling distribution indicates the distribution of points in a single sample.
(Question ID: 0706186408)
The Central Limit Theorem states that, in large samples, sampling distributions are approximately normal.
(Question ID: 0096886069)
If a population is normally distributed, all sampling distributions related to it will also be normal.
(Question ID: 0344389365)
A sampling distribution is the distribution of a statistic.
(Question ID: 0596239551)
Confidence intervals have probabilities that are calibrated on the basis of sampling distributions.
(Question ID: 0223081713)
A sampling distribution is the distribution of a statistic.
(Question ID: 0906859124)
The sampling distribution depends on the population distribution, statistic being considered, and the sample size.
(Question ID: 0405150885)
A sampling distribution is the distribution of a statistic.
(Question ID: 0270748397)
The sampling distribution is an estimate of the population distribution.
(Question ID: 0054315215)
Confidence intervals have probabilities that are calibrated on the basis of sampling distributions.
(Question ID: 0182305286)
If a population is normally distributed, all sampling distributions related to it will also be normal.
(Question ID: 0462598950)
If a population is normally distributed, all sampling distributions related to it will also be normal.
(Question ID: 0072294476)
Confidence intervals have probabilities that are calibrated on the basis of sampling distributions.
(Question ID: 0014340824)
A sampling distribution is the distribution of a statistic.
(Question ID: 0627915722)
The Central Limit Theorem states that, in large samples, sampling distributions are approximately normal.
(Question ID: 0364696965)
Confidence intervals have probabilities that are calibrated on the basis of sampling distributions.
(Question ID: 0809684567)
The sampling distribution indicates the distribution of points in a single sample.
(Question ID: 0768452451)
A single computed statistic can be viewed as a realization from its sampling distribution.
(Question ID: 0394146805)
The standard deviation of a sampling distribution is referred to as the standard error.
(Question ID: 0109453452)
The standard deviation of a sampling distribution is referred to as the standard error.
(Question ID: 0697175778)
If a sampling distribution is known, it can be used for probability calculations relating to the values of statistics.
(Question ID: 0435420953)
The Central Limit Theorem states that, in large samples, sampling distributions are approximately normal.
(Question ID: 0845641218)
The Central Limit Theorem states that, in large samples, sampling distributions are approximately normal.
(Question ID: 0131795112)
Confidence intervals have probabilities that are calibrated on the basis of sampling distributions.
(Question ID: 0895720886)
The sampling distribution is an estimate of the population distribution.
(Question ID: 0179064140)
The sample variance and sample mean give the values of the variance and mean for the sampling distribution.
(Question ID: 0165761113)
The standard deviation of a sampling distribution is referred to as the standard error.
(Question ID: 0901291310)
If a population is normally distributed, all sampling distributions related to it will also be normal.
(Question ID: 0412403743)
Suppose that you are told that the sampling distribution of the mean concentration of a pollutant in a water sample is \(N(26, 4)\), based on a random sample of size \(80\).
- What is the probability that the calculated mean will exceed 27?
- If the sample size had been 108 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 108 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 108 is taken. What is the probability that the calculated mean does not exceed 24.6?
Question ID: 0792725069
Suppose that you are told that the sampling distribution of the mean diameter (in millimeters) of a certain type of seed is \(N(64, 1)\), based on a random sample of size \(32\).
- What is the probability that the calculated mean will exceed 65?
- If the sample size had been 81 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 81 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 81 is taken. What is the probability that the calculated mean does not exceed 63.7?
Question ID: 0274089103
Suppose that you are told that the sampling distribution of the mean time taken to complete a simple task is \(N(49, 4)\), based on a random sample of size \(46\).
- What is the probability that the calculated mean will exceed 53?
- If the sample size had been 51 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 51 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 51 is taken. What is the probability that the calculated mean does not exceed 51.2?
Question ID: 0568286869
Suppose that you are told that the sampling distribution of the mean electrical resistance of a specific type of resistor is \(N(32, 4)\), based on a random sample of size \(81\).
- What is the probability that the calculated mean will exceed 33?
- If the sample size had been 176 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 176 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 176 is taken. What is the probability that the calculated mean does not exceed 33.3?
Question ID: 0349656819
Suppose that you are told that the sampling distribution of the mean daily rainfall in a city during a specific month is \(N(25, 1)\), based on a random sample of size \(48\).
- What is the probability that the calculated mean will exceed 25?
- If the sample size had been 91 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 91 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 91 is taken. What is the probability that the calculated mean does not exceed 24.5?
Question ID: 0277743272
Suppose that you are told that the sampling distribution of the mean diameter (in millimeters) of a certain type of seed is \(N(75, 4)\), based on a random sample of size \(82\).
- What is the probability that the calculated mean will exceed 73?
- If the sample size had been 93 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 93 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 93 is taken. What is the probability that the calculated mean does not exceed 75.2?
Question ID: 0181438981
Suppose that you are told that the sampling distribution of the mean concentration of a pollutant in a water sample is \(N(38, 9)\), based on a random sample of size \(40\).
- What is the probability that the calculated mean will exceed 39?
- If the sample size had been 83 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 83 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 83 is taken. What is the probability that the calculated mean does not exceed 41.8?
Question ID: 0043618282
Suppose that you are told that the sampling distribution of the mean score of students on a standardized test is \(N(75, 9)\), based on a random sample of size \(72\).
- What is the probability that the calculated mean will exceed 73?
- If the sample size had been 82 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 82 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 82 is taken. What is the probability that the calculated mean does not exceed 80.4?
Question ID: 0502419456
Suppose that you are told that the sampling distribution of the mean concentration of a pollutant in a water sample is \(N(8, 1)\), based on a random sample of size \(59\).
- What is the probability that the calculated mean will exceed 7?
- If the sample size had been 82 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 82 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 82 is taken. What is the probability that the calculated mean does not exceed 6.3?
Question ID: 0450244226
Suppose that you are told that the sampling distribution of the mean length of leaves from a particular tree species is \(N(22, 1)\), based on a random sample of size \(74\).
- What is the probability that the calculated mean will exceed 22?
- If the sample size had been 146 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 146 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 146 is taken. What is the probability that the calculated mean does not exceed 21.6?
Question ID: 0899283672
Suppose that you are told that the sampling distribution of the mean electrical resistance of a specific type of resistor is \(N(10, 4)\), based on a random sample of size \(61\).
- What is the probability that the calculated mean will exceed 11?
- If the sample size had been 97 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 97 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 97 is taken. What is the probability that the calculated mean does not exceed 6.8?
Question ID: 0718195761
Suppose that you are told that the sampling distribution of the mean diameter (in millimeters) of a certain type of seed is \(N(38, 4)\), based on a random sample of size \(51\).
- What is the probability that the calculated mean will exceed 34?
- If the sample size had been 154 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 154 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 154 is taken. What is the probability that the calculated mean does not exceed 38.7?
Question ID: 0396986507
Suppose that you are told that the sampling distribution of the mean temperature (in degrees Celsius) of products in a chemical reaction is \(N(58, 1)\), based on a random sample of size \(38\).
- What is the probability that the calculated mean will exceed 57?
- If the sample size had been 56 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 56 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 56 is taken. What is the probability that the calculated mean does not exceed 59.4?
Question ID: 0123070417
Suppose that you are told that the sampling distribution of the mean score of students on a standardized test is \(N(55, 1)\), based on a random sample of size \(70\).
- What is the probability that the calculated mean will exceed 57?
- If the sample size had been 128 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 128 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 128 is taken. What is the probability that the calculated mean does not exceed 55.5?
Question ID: 0297611100
Suppose that you are told that the sampling distribution of the mean temperature (in degrees Celsius) of products in a chemical reaction is \(N(37, 4)\), based on a random sample of size \(82\).
- What is the probability that the calculated mean will exceed 34?
- If the sample size had been 131 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 131 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 131 is taken. What is the probability that the calculated mean does not exceed 33.8?
Question ID: 0227616038
Suppose that you are told that the sampling distribution of the mean electrical resistance of a specific type of resistor is \(N(63, 4)\), based on a random sample of size \(46\).
- What is the probability that the calculated mean will exceed 60?
- If the sample size had been 144 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 144 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 144 is taken. What is the probability that the calculated mean does not exceed 61.7?
Question ID: 0105950044
Suppose that you are told that the sampling distribution of the mean flow rate of a liquid through a pipe is \(N(32, 1)\), based on a random sample of size \(34\).
- What is the probability that the calculated mean will exceed 34?
- If the sample size had been 132 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 132 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 132 is taken. What is the probability that the calculated mean does not exceed 31?
Question ID: 0089151771
Suppose that you are told that the sampling distribution of the mean diameter (in millimeters) of a certain type of seed is \(N(48, 1)\), based on a random sample of size \(91\).
- What is the probability that the calculated mean will exceed 49?
- If the sample size had been 133 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 133 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 133 is taken. What is the probability that the calculated mean does not exceed 46.3?
Question ID: 0539903946
Suppose that you are told that the sampling distribution of the mean temperature (in degrees Celsius) of products in a chemical reaction is \(N(72, 1)\), based on a random sample of size \(57\).
- What is the probability that the calculated mean will exceed 73?
- If the sample size had been 66 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 66 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 66 is taken. What is the probability that the calculated mean does not exceed 70.1?
Question ID: 0750412833
Suppose that you are told that the sampling distribution of the mean time taken to complete a simple task is \(N(54, 1)\), based on a random sample of size \(87\).
- What is the probability that the calculated mean will exceed 56?
- If the sample size had been 172 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 172 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 172 is taken. What is the probability that the calculated mean does not exceed 54.6?
Question ID: 0101482857
Suppose that you are told that the sampling distribution of the mean length of leaves from a particular tree species is \(N(45, 4)\), based on a random sample of size \(78\).
- What is the probability that the calculated mean will exceed 43?
- If the sample size had been 185 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 185 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 185 is taken. What is the probability that the calculated mean does not exceed 47.4?
Question ID: 0686843708
Suppose that you are told that the sampling distribution of the mean temperature (in degrees Celsius) of products in a chemical reaction is \(N(29, 1)\), based on a random sample of size \(67\).
- What is the probability that the calculated mean will exceed 30?
- If the sample size had been 68 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 68 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 68 is taken. What is the probability that the calculated mean does not exceed 29?
Question ID: 0096764049
Suppose that you are told that the sampling distribution of the mean length of leaves from a particular tree species is \(N(32, 1)\), based on a random sample of size \(62\).
- What is the probability that the calculated mean will exceed 34?
- If the sample size had been 171 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 171 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 171 is taken. What is the probability that the calculated mean does not exceed 30.8?
Question ID: 0233321781
Suppose that you are told that the sampling distribution of the mean flow rate of a liquid through a pipe is \(N(37, 1)\), based on a random sample of size \(89\).
- What is the probability that the calculated mean will exceed 38?
- If the sample size had been 97 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 97 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 97 is taken. What is the probability that the calculated mean does not exceed 37.1?
Question ID: 0528297641
Suppose that you are told that the sampling distribution of the mean temperature (in degrees Celsius) of products in a chemical reaction is \(N(75, 1)\), based on a random sample of size \(95\).
- What is the probability that the calculated mean will exceed 76?
- If the sample size had been 144 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 144 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 144 is taken. What is the probability that the calculated mean does not exceed 76.4?
Question ID: 0590630894
Suppose that you are told that the sampling distribution of the mean diameter (in millimeters) of a certain type of seed is \(N(46, 9)\), based on a random sample of size \(37\).
- What is the probability that the calculated mean will exceed 40?
- If the sample size had been 108 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 108 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 108 is taken. What is the probability that the calculated mean does not exceed 45.5?
Question ID: 0332955951
Suppose that you are told that the sampling distribution of the mean diameter (in millimeters) of a certain type of seed is \(N(74, 4)\), based on a random sample of size \(95\).
- What is the probability that the calculated mean will exceed 76?
- If the sample size had been 111 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 111 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 111 is taken. What is the probability that the calculated mean does not exceed 77.3?
Question ID: 0530460915
Suppose that you are told that the sampling distribution of the mean length of leaves from a particular tree species is \(N(25, 4)\), based on a random sample of size \(72\).
- What is the probability that the calculated mean will exceed 25?
- If the sample size had been 150 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 150 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 150 is taken. What is the probability that the calculated mean does not exceed 25.2?
Question ID: 0442848766
Suppose that you are told that the sampling distribution of the mean flow rate of a liquid through a pipe is \(N(36, 1)\), based on a random sample of size \(94\).
- What is the probability that the calculated mean will exceed 34?
- If the sample size had been 154 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 154 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 154 is taken. What is the probability that the calculated mean does not exceed 36.4?
Question ID: 0020206421
Suppose that you are told that the sampling distribution of the mean score of students on a standardized test is \(N(30, 1)\), based on a random sample of size \(39\).
- What is the probability that the calculated mean will exceed 32?
- If the sample size had been 61 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 61 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 61 is taken. What is the probability that the calculated mean does not exceed 29.4?
Question ID: 0401650822
Suppose that you are told that the sampling distribution of the mean length of leaves from a particular tree species is \(N(5, 1)\), based on a random sample of size \(77\).
- What is the probability that the calculated mean will exceed 6?
- If the sample size had been 188 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 188 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 188 is taken. What is the probability that the calculated mean does not exceed 5.7?
Question ID: 0784115828
Suppose that you are told that the sampling distribution of the mean daily rainfall in a city during a specific month is \(N(43, 9)\), based on a random sample of size \(42\).
- What is the probability that the calculated mean will exceed 38?
- If the sample size had been 162 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 162 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 162 is taken. What is the probability that the calculated mean does not exceed 40.9?
Question ID: 0881478041
Suppose that you are told that the sampling distribution of the mean diameter (in millimeters) of a certain type of seed is \(N(65, 9)\), based on a random sample of size \(92\).
- What is the probability that the calculated mean will exceed 69?
- If the sample size had been 100 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 100 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 100 is taken. What is the probability that the calculated mean does not exceed 67.2?
Question ID: 0731017474
Suppose that you are told that the sampling distribution of the mean flow rate of a liquid through a pipe is \(N(37, 4)\), based on a random sample of size \(78\).
- What is the probability that the calculated mean will exceed 36?
- If the sample size had been 143 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 143 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 143 is taken. What is the probability that the calculated mean does not exceed 38?
Question ID: 0316381104
Suppose that you are told that the sampling distribution of the mean time taken to complete a simple task is \(N(17, 4)\), based on a random sample of size \(85\).
- What is the probability that the calculated mean will exceed 21?
- If the sample size had been 92 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 92 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 92 is taken. What is the probability that the calculated mean does not exceed 18.2?
Question ID: 0369765851
Suppose that you are told that the sampling distribution of the mean growth rate of a young tree is \(N(10, 1)\), based on a random sample of size \(50\).
- What is the probability that the calculated mean will exceed 8?
- If the sample size had been 197 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 197 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 197 is taken. What is the probability that the calculated mean does not exceed 9?
Question ID: 0321980101
Suppose that you are told that the sampling distribution of the mean length of leaves from a particular tree species is \(N(31, 1)\), based on a random sample of size \(37\).
- What is the probability that the calculated mean will exceed 33?
- If the sample size had been 105 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 105 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 105 is taken. What is the probability that the calculated mean does not exceed 30.8?
Question ID: 0318652294
Suppose that you are told that the sampling distribution of the mean growth rate of a young tree is \(N(19, 4)\), based on a random sample of size \(73\).
- What is the probability that the calculated mean will exceed 17?
- If the sample size had been 161 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 161 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 161 is taken. What is the probability that the calculated mean does not exceed 21.3?
Question ID: 0667779673
Suppose that you are told that the sampling distribution of the mean pressure within a closed container is \(N(23, 4)\), based on a random sample of size \(82\).
- What is the probability that the calculated mean will exceed 23?
- If the sample size had been 117 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 117 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 117 is taken. What is the probability that the calculated mean does not exceed 25.7?
Question ID: 0268244531
Suppose that you are told that the sampling distribution of the mean growth rate of a young tree is \(N(9, 1)\), based on a random sample of size \(85\).
- What is the probability that the calculated mean will exceed 11?
- If the sample size had been 123 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 123 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 123 is taken. What is the probability that the calculated mean does not exceed 8.3?
Question ID: 0319050189
Suppose that you are told that the sampling distribution of the mean electrical resistance of a specific type of resistor is \(N(33, 4)\), based on a random sample of size \(85\).
- What is the probability that the calculated mean will exceed 30?
- If the sample size had been 184 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 184 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 184 is taken. What is the probability that the calculated mean does not exceed 34.3?
Question ID: 0804489805
Suppose that you are told that the sampling distribution of the mean score of students on a standardized test is \(N(26, 1)\), based on a random sample of size \(80\).
- What is the probability that the calculated mean will exceed 28?
- If the sample size had been 89 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 89 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 89 is taken. What is the probability that the calculated mean does not exceed 26.1?
Question ID: 0084940653
Suppose that you are told that the sampling distribution of the mean length of time that customer visit a store is \(N(60, 4)\), based on a random sample of size \(78\).
- What is the probability that the calculated mean will exceed 64?
- If the sample size had been 111 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 111 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 111 is taken. What is the probability that the calculated mean does not exceed 57.6?
Question ID: 0952948601
Suppose that you are told that the sampling distribution of the mean pressure within a closed container is \(N(32, 1)\), based on a random sample of size \(72\).
- What is the probability that the calculated mean will exceed 32?
- If the sample size had been 175 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 175 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 175 is taken. What is the probability that the calculated mean does not exceed 32.7?
Question ID: 0418822381
Suppose that you are told that the sampling distribution of the mean flow rate of a liquid through a pipe is \(N(43, 1)\), based on a random sample of size \(80\).
- What is the probability that the calculated mean will exceed 42?
- If the sample size had been 106 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 106 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 106 is taken. What is the probability that the calculated mean does not exceed 44.3?
Question ID: 0867886375
Suppose that you are told that the sampling distribution of the mean pressure within a closed container is \(N(47, 9)\), based on a random sample of size \(40\).
- What is the probability that the calculated mean will exceed 50?
- If the sample size had been 200 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 200 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 200 is taken. What is the probability that the calculated mean does not exceed 47.3?
Question ID: 0951700812
Suppose that you are told that the sampling distribution of the mean temperature (in degrees Celsius) of products in a chemical reaction is \(N(67, 1)\), based on a random sample of size \(92\).
- What is the probability that the calculated mean will exceed 66?
- If the sample size had been 131 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 131 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 131 is taken. What is the probability that the calculated mean does not exceed 66.3?
Question ID: 0278074922
Suppose that you are told that the sampling distribution of the mean time taken to complete a simple task is \(N(72, 9)\), based on a random sample of size \(93\).
- What is the probability that the calculated mean will exceed 78?
- If the sample size had been 104 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 104 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 104 is taken. What is the probability that the calculated mean does not exceed 69.3?
Question ID: 0109350317
Suppose that you are told that the sampling distribution of the mean flow rate of a liquid through a pipe is \(N(46, 4)\), based on a random sample of size \(31\).
- What is the probability that the calculated mean will exceed 43?
- If the sample size had been 100 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 100 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 100 is taken. What is the probability that the calculated mean does not exceed 46.8?
Question ID: 0227274256
Suppose that you are told that the sampling distribution of the mean temperature (in degrees Celsius) of products in a chemical reaction is \(N(20, 4)\), based on a random sample of size \(59\).
- What is the probability that the calculated mean will exceed 23?
- If the sample size had been 73 instead, what would the mean of the sampling distribution have been?
- If the sample size had been 73 instead, what would the variance of the sampling distribution have been?
- Suppose that a sample of size 73 is taken. What is the probability that the calculated mean does not exceed 22.4?
Question ID: 0954734289
A brewery is filling bottles with beer. The target volume per bottle is 747 mL.
Owing to unintentional variations, the beer volume is a random quantity, with a mean of 747.33 and a standard deviation of 2.2 mL.
Consider taking the mean beer volume based on a sample of 256 bottles?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 747 mL?
- What is the probability that the sample mean is within 0.39 mL of 747?
Question ID: 0626724472
A construction crew is laying a section of pipe. The target length for a section is 38 meters.
Owing to unintentional variations, the pipe length is a random quantity, with a mean of 38.01 and a standard deviation of 0.06 meters.
Consider taking the mean pipe length based on a sample of 100 sections?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 38 meters?
- What is the probability that the sample mean is within 0.01 meters of 38?
Question ID: 0114924758
A tailor is cutting fabric for a suit. The required length of a specific piece is 84 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 85.04 and a standard deviation of 4.6 cm.
Consider taking the mean fabric length based on a sample of 121 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 84 cm?
- What is the probability that the sample mean is within 0.26 cm of 84?
Question ID: 0521312138
A brewery is filling bottles with beer. The target volume per bottle is 301 mL.
Owing to unintentional variations, the beer volume is a random quantity, with a mean of 301.07 and a standard deviation of 0.7 mL.
Consider taking the mean beer volume based on a sample of 289 bottles?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 301 mL?
- What is the probability that the sample mean is within 0 mL of 301?
Question ID: 0875982921
A factory produces light bulbs. The target lifespan for these bulbs is 1085 hours.
Owing to unintentional variations, the bulb lifespan is a random quantity, with a mean of 1108.74 and a standard deviation of 149 hours.
Consider taking the mean bulb lifespan based on a sample of 324 bulbs?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 1085 hours?
- What is the probability that the sample mean is within 3.22 hours of 1085?
Question ID: 0447871257
A tailor is cutting fabric for a suit. The required length of a specific piece is 110 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 110.82 and a standard deviation of 2.8 cm.
Consider taking the mean fabric length based on a sample of 100 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 110 cm?
- What is the probability that the sample mean is within 0.65 cm of 110?
Question ID: 0623375413
A tailor is cutting fabric for a suit. The required length of a specific piece is 120 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 120.72 and a standard deviation of 4.7 cm.
Consider taking the mean fabric length based on a sample of 256 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 120 cm?
- What is the probability that the sample mean is within 0.63 cm of 120?
Question ID: 0864171947
A farmer is harvesting apples from an orchard. The desired yield from a particular tree is 124 kilograms.
Owing to unintentional variations, the apple yield is a random quantity, with a mean of 125.01 and a standard deviation of 9 kilograms.
Consider taking the mean apple yield based on a sample of 169 trees?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 124 kilograms?
- What is the probability that the sample mean is within 1.19 kilograms of 124?
Question ID: 0092652688
A factory produces light bulbs. The target lifespan for these bulbs is 3575 hours.
Owing to unintentional variations, the bulb lifespan is a random quantity, with a mean of 3581.29 and a standard deviation of 158 hours.
Consider taking the mean bulb lifespan based on a sample of 324 bulbs?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 3575 hours?
- What is the probability that the sample mean is within 17.3 hours of 3575?
Question ID: 0363739129
A tailor is cutting fabric for a suit. The required length of a specific piece is 142 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 142.6 and a standard deviation of 4.9 cm.
Consider taking the mean fabric length based on a sample of 81 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 142 cm?
- What is the probability that the sample mean is within 1.56 cm of 142?
Question ID: 0322085096
A pharmaceutical company is manufacturing tablets. Each tablet should contain exactly 256 mg.
Owing to unintentional variations, the active ingredient weight is a random quantity, with a mean of 256.01 and a standard deviation of 0.51 mg.
Consider taking the mean active ingredient weight based on a sample of 400 tablets?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 256 mg?
- What is the probability that the sample mean is within 0.04 mg of 256?
Question ID: 0617731606
A tailor is cutting fabric for a suit. The required length of a specific piece is 86 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 86.87 and a standard deviation of 3.8 cm.
Consider taking the mean fabric length based on a sample of 169 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 86 cm?
- What is the probability that the sample mean is within 0.77 cm of 86?
Question ID: 0764666887
A farmer is harvesting apples from an orchard. The desired yield from a particular tree is 198 kilograms.
Owing to unintentional variations, the apple yield is a random quantity, with a mean of 199.06 and a standard deviation of 11 kilograms.
Consider taking the mean apple yield based on a sample of 64 trees?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 198 kilograms?
- What is the probability that the sample mean is within 0.56 kilograms of 198?
Question ID: 0698599289
A farmer is harvesting apples from an orchard. The desired yield from a particular tree is 124 kilograms.
Owing to unintentional variations, the apple yield is a random quantity, with a mean of 124.52 and a standard deviation of 11 kilograms.
Consider taking the mean apple yield based on a sample of 256 trees?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 124 kilograms?
- What is the probability that the sample mean is within 0.87 kilograms of 124?
Question ID: 0199663448
A farmer is harvesting apples from an orchard. The desired yield from a particular tree is 114 kilograms.
Owing to unintentional variations, the apple yield is a random quantity, with a mean of 114.97 and a standard deviation of 7 kilograms.
Consider taking the mean apple yield based on a sample of 100 trees?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 114 kilograms?
- What is the probability that the sample mean is within 0.16 kilograms of 114?
Question ID: 0183261431
A tailor is cutting fabric for a suit. The required length of a specific piece is 198 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 198.74 and a standard deviation of 4.1 cm.
Consider taking the mean fabric length based on a sample of 256 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 198 cm?
- What is the probability that the sample mean is within 0.21 cm of 198?
Question ID: 0084053904
A construction crew is laying a section of pipe. The target length for a section is 47 meters.
Owing to unintentional variations, the pipe length is a random quantity, with a mean of 47.07 and a standard deviation of 0.45 meters.
Consider taking the mean pipe length based on a sample of 361 sections?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 47 meters?
- What is the probability that the sample mean is within 0.05 meters of 47?
Question ID: 0333915936
A call center aims to handle a certain number of calls per hour. The target for an hour is 83 calls.
Owing to unintentional variations, the calls handled is a random quantity, with a mean of 84.25 and a standard deviation of 9 calls.
Consider taking the mean calls handled based on a sample of 196 hours?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 83 calls?
- What is the probability that the sample mean is within 1.71 calls of 83?
Question ID: 0482033972
A brewery is filling bottles with beer. The target volume per bottle is 324 mL.
Owing to unintentional variations, the beer volume is a random quantity, with a mean of 324.14 and a standard deviation of 1 mL.
Consider taking the mean beer volume based on a sample of 121 bottles?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 324 mL?
- What is the probability that the sample mean is within 0.21 mL of 324?
Question ID: 0009321237
A machine at a factory fills containers with a liquid. The goal is to fill the container with exactly 345 mL.
Owing to unintentional variations, the fill amount is a random quantity, with a mean of 345.15 and a standard deviation of 0.65 mL.
Consider taking the mean fill amount based on a sample of 100 fills?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 345 mL?
- What is the probability that the sample mean is within 0.05 mL of 345?
Question ID: 0336693139
A construction crew is laying a section of pipe. The target length for a section is 16 meters.
Owing to unintentional variations, the pipe length is a random quantity, with a mean of 16.03 and a standard deviation of 0.25 meters.
Consider taking the mean pipe length based on a sample of 100 sections?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 16 meters?
- What is the probability that the sample mean is within 0.03 meters of 16?
Question ID: 0171044340
A farmer is harvesting apples from an orchard. The desired yield from a particular tree is 104 kilograms.
Owing to unintentional variations, the apple yield is a random quantity, with a mean of 105.46 and a standard deviation of 7 kilograms.
Consider taking the mean apple yield based on a sample of 144 trees?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 104 kilograms?
- What is the probability that the sample mean is within 0.73 kilograms of 104?
Question ID: 0213073253
A baker is making a batch of cookies. The recipe calls for a total dough weight of 1358 grams.
Owing to unintentional variations, the dough weight is a random quantity, with a mean of 1358.37 and a standard deviation of 7 grams.
Consider taking the mean dough weight based on a sample of 144 batches?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 1358 grams?
- What is the probability that the sample mean is within 1 grams of 1358?
Question ID: 0773014054
A factory produces light bulbs. The target lifespan for these bulbs is 3378 hours.
Owing to unintentional variations, the bulb lifespan is a random quantity, with a mean of 3399.6 and a standard deviation of 172 hours.
Consider taking the mean bulb lifespan based on a sample of 225 bulbs?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 3378 hours?
- What is the probability that the sample mean is within 23.14 hours of 3378?
Question ID: 0585833365
A factory produces light bulbs. The target lifespan for these bulbs is 4838 hours.
Owing to unintentional variations, the bulb lifespan is a random quantity, with a mean of 4851.04 and a standard deviation of 81 hours.
Consider taking the mean bulb lifespan based on a sample of 169 bulbs?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 4838 hours?
- What is the probability that the sample mean is within 14.24 hours of 4838?
Question ID: 0613817563
A tailor is cutting fabric for a suit. The required length of a specific piece is 92 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 92.56 and a standard deviation of 2.4 cm.
Consider taking the mean fabric length based on a sample of 100 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 92 cm?
- What is the probability that the sample mean is within 0.48 cm of 92?
Question ID: 0044954556
A construction crew is laying a section of pipe. The target length for a section is 21 meters.
Owing to unintentional variations, the pipe length is a random quantity, with a mean of 21.01 and a standard deviation of 0.31 meters.
Consider taking the mean pipe length based on a sample of 225 sections?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 21 meters?
- What is the probability that the sample mean is within 0 meters of 21?
Question ID: 0995661169
A baker is making a batch of cookies. The recipe calls for a total dough weight of 655 grams.
Owing to unintentional variations, the dough weight is a random quantity, with a mean of 655.06 and a standard deviation of 7 grams.
Consider taking the mean dough weight based on a sample of 256 batches?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 655 grams?
- What is the probability that the sample mean is within 0.09 grams of 655?
Question ID: 0974624439
A machine at a factory fills containers with a liquid. The goal is to fill the container with exactly 452 mL.
Owing to unintentional variations, the fill amount is a random quantity, with a mean of 452.08 and a standard deviation of 0.23 mL.
Consider taking the mean fill amount based on a sample of 81 fills?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 452 mL?
- What is the probability that the sample mean is within 0.05 mL of 452?
Question ID: 0521900897
A brewery is filling bottles with beer. The target volume per bottle is 684 mL.
Owing to unintentional variations, the beer volume is a random quantity, with a mean of 684.06 and a standard deviation of 2.3 mL.
Consider taking the mean beer volume based on a sample of 169 bottles?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 684 mL?
- What is the probability that the sample mean is within 0.21 mL of 684?
Question ID: 0875088617
A farmer is harvesting apples from an orchard. The desired yield from a particular tree is 159 kilograms.
Owing to unintentional variations, the apple yield is a random quantity, with a mean of 160.09 and a standard deviation of 10 kilograms.
Consider taking the mean apple yield based on a sample of 361 trees?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 159 kilograms?
- What is the probability that the sample mean is within 0.66 kilograms of 159?
Question ID: 0174270692
A machine at a factory fills containers with a liquid. The goal is to fill the container with exactly 189 mL.
Owing to unintentional variations, the fill amount is a random quantity, with a mean of 189.03 and a standard deviation of 0.62 mL.
Consider taking the mean fill amount based on a sample of 169 fills?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 189 mL?
- What is the probability that the sample mean is within 0.02 mL of 189?
Question ID: 0476190779
A brewery is filling bottles with beer. The target volume per bottle is 602 mL.
Owing to unintentional variations, the beer volume is a random quantity, with a mean of 602.01 and a standard deviation of 1.7 mL.
Consider taking the mean beer volume based on a sample of 400 bottles?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 602 mL?
- What is the probability that the sample mean is within 0.24 mL of 602?
Question ID: 0329639261
A farmer is harvesting apples from an orchard. The desired yield from a particular tree is 129 kilograms.
Owing to unintentional variations, the apple yield is a random quantity, with a mean of 129.56 and a standard deviation of 9 kilograms.
Consider taking the mean apple yield based on a sample of 256 trees?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 129 kilograms?
- What is the probability that the sample mean is within 0.36 kilograms of 129?
Question ID: 0549551081
A tailor is cutting fabric for a suit. The required length of a specific piece is 141 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 141.47 and a standard deviation of 3 cm.
Consider taking the mean fabric length based on a sample of 100 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 141 cm?
- What is the probability that the sample mean is within 0.24 cm of 141?
Question ID: 0998389510
A machine at a factory fills containers with a liquid. The goal is to fill the container with exactly 226 mL.
Owing to unintentional variations, the fill amount is a random quantity, with a mean of 226.03 and a standard deviation of 0.61 mL.
Consider taking the mean fill amount based on a sample of 196 fills?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 226 mL?
- What is the probability that the sample mean is within 0.05 mL of 226?
Question ID: 0190008803
A pharmaceutical company is manufacturing tablets. Each tablet should contain exactly 318 mg.
Owing to unintentional variations, the active ingredient weight is a random quantity, with a mean of 318.06 and a standard deviation of 0.41 mg.
Consider taking the mean active ingredient weight based on a sample of 361 tablets?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 318 mg?
- What is the probability that the sample mean is within 0.01 mg of 318?
Question ID: 0124449638
A factory produces light bulbs. The target lifespan for these bulbs is 3015 hours.
Owing to unintentional variations, the bulb lifespan is a random quantity, with a mean of 3032.35 and a standard deviation of 137 hours.
Consider taking the mean bulb lifespan based on a sample of 289 bulbs?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 3015 hours?
- What is the probability that the sample mean is within 1.62 hours of 3015?
Question ID: 0005589282
A tailor is cutting fabric for a suit. The required length of a specific piece is 84 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 84.14 and a standard deviation of 2.3 cm.
Consider taking the mean fabric length based on a sample of 324 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 84 cm?
- What is the probability that the sample mean is within 0.07 cm of 84?
Question ID: 0747536362
A machine at a factory fills containers with a liquid. The goal is to fill the container with exactly 483 mL.
Owing to unintentional variations, the fill amount is a random quantity, with a mean of 483 and a standard deviation of 0.56 mL.
Consider taking the mean fill amount based on a sample of 361 fills?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 483 mL?
- What is the probability that the sample mean is within 0.02 mL of 483?
Question ID: 0715159022
A baker is making a batch of cookies. The recipe calls for a total dough weight of 841 grams.
Owing to unintentional variations, the dough weight is a random quantity, with a mean of 841.71 and a standard deviation of 5 grams.
Consider taking the mean dough weight based on a sample of 100 batches?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 841 grams?
- What is the probability that the sample mean is within 0.85 grams of 841?
Question ID: 0402401379
A tailor is cutting fabric for a suit. The required length of a specific piece is 50 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 50.52 and a standard deviation of 3.4 cm.
Consider taking the mean fabric length based on a sample of 289 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 50 cm?
- What is the probability that the sample mean is within 0.33 cm of 50?
Question ID: 0274322691
A pharmaceutical company is manufacturing tablets. Each tablet should contain exactly 393 mg.
Owing to unintentional variations, the active ingredient weight is a random quantity, with a mean of 393.18 and a standard deviation of 1.73 mg.
Consider taking the mean active ingredient weight based on a sample of 361 tablets?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 393 mg?
- What is the probability that the sample mean is within 0.05 mg of 393?
Question ID: 0226249908
A construction crew is laying a section of pipe. The target length for a section is 15 meters.
Owing to unintentional variations, the pipe length is a random quantity, with a mean of 15 and a standard deviation of 0.13 meters.
Consider taking the mean pipe length based on a sample of 289 sections?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 15 meters?
- What is the probability that the sample mean is within 0.01 meters of 15?
Question ID: 0555533064
A machine at a factory fills containers with a liquid. The goal is to fill the container with exactly 136 mL.
Owing to unintentional variations, the fill amount is a random quantity, with a mean of 136.06 and a standard deviation of 0.61 mL.
Consider taking the mean fill amount based on a sample of 196 fills?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 136 mL?
- What is the probability that the sample mean is within 0.11 mL of 136?
Question ID: 0313784150
A brewery is filling bottles with beer. The target volume per bottle is 680 mL.
Owing to unintentional variations, the beer volume is a random quantity, with a mean of 680.1 and a standard deviation of 1.6 mL.
Consider taking the mean beer volume based on a sample of 361 bottles?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 680 mL?
- What is the probability that the sample mean is within 0.08 mL of 680?
Question ID: 0811230931
A tailor is cutting fabric for a suit. The required length of a specific piece is 192 cm.
Owing to unintentional variations, the fabric length is a random quantity, with a mean of 192.25 and a standard deviation of 3.1 cm.
Consider taking the mean fabric length based on a sample of 196 pieces?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 192 cm?
- What is the probability that the sample mean is within 0.59 cm of 192?
Question ID: 0878518527
A pharmaceutical company is manufacturing tablets. Each tablet should contain exactly 433 mg.
Owing to unintentional variations, the active ingredient weight is a random quantity, with a mean of 433.17 and a standard deviation of 1.09 mg.
Consider taking the mean active ingredient weight based on a sample of 324 tablets?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 433 mg?
- What is the probability that the sample mean is within 0.16 mg of 433?
Question ID: 0881162347
A factory produces light bulbs. The target lifespan for these bulbs is 2696 hours.
Owing to unintentional variations, the bulb lifespan is a random quantity, with a mean of 2717.41 and a standard deviation of 166 hours.
Consider taking the mean bulb lifespan based on a sample of 289 bulbs?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 2696 hours?
- What is the probability that the sample mean is within 26.49 hours of 2696?
Question ID: 0285842660
A farmer is harvesting apples from an orchard. The desired yield from a particular tree is 152 kilograms.
Owing to unintentional variations, the apple yield is a random quantity, with a mean of 153.77 and a standard deviation of 6 kilograms.
Consider taking the mean apple yield based on a sample of 64 trees?
- What is the mean of the sampling distribution of the sample mean?
- What is the standard deviation of the sampling distribution of the sample mean?
- What is the probability that the sample mean is less than 152 kilograms?
- What is the probability that the sample mean is within 0.14 kilograms of 152?
Question ID: 0170025117
Considering a group of surveyed households, \(21\%\) own more than one vehicle. A simple random sample of \(5,000\) households is taken.
Let \(X\) denote the number of households sampled that own more than one vehicle.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.2?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.201?
Question ID: 0657134015
In a population of wild deer, \(12\%\) carry a specific genetic marker. A simple random sample of \(3,800\) deer is taken.
Let \(X\) denote the number of deer sampled that carry a specific genetic marker.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.124?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.129?
Question ID: 0869287015
Within a flock of migratory birds, \(30\%\) have been fitted with tracking devices. A simple random sample of \(1,600\) birds is taken.
Let \(X\) denote the number of birds sampled that have been fitted with tracking devices.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.295?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.303?
Question ID: 0122439024
Within a colony of honeybees, \(3\%\) are observed performing waggle dances. A simple random sample of \(2,700\) bees is taken.
Let \(X\) denote the number of bees sampled that are observed performing waggle dances.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.027?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.033?
Question ID: 0506089586
Examining a batch of manufactured widgets, \(11\%\) are found to be defective. A simple random sample of \(1,800\) widgets is taken.
Let \(X\) denote the number of widgets sampled that are found to be defective.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.102?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.107?
Question ID: 0912539652
Among adults in a large city, \(20\%\) attended university. A simple random sample of \(2,300\) adults is taken.
Let \(X\) denote the number of adults sampled who attended university.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.184?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.193?
Question ID: 0597909996
Looking at a collection of antique coins, \(20\%\) are made of silver. A simple random sample of \(4,900\) coins is taken.
Let \(X\) denote the number of coins sampled that are made of silver.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.203?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.197?
Question ID: 0798432172
Among registered voters in a province, \(34\%\) intend to vote in the upcoming election. A simple random sample of \(4,900\) voters is taken.
Let \(X\) denote the number of voters sampled who intend to vote in the upcoming election.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.34?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.326?
Question ID: 0531651152
Examining a batch of manufactured widgets, \(13\%\) are found to be defective. A simple random sample of \(4,300\) widgets is taken.
Let \(X\) denote the number of widgets sampled that are found to be defective.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.117?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.117?
Question ID: 0465535869
Within a colony of honeybees, \(4\%\) are observed performing waggle dances. A simple random sample of \(1,100\) bees is taken.
Let \(X\) denote the number of bees sampled that are observed performing waggle dances.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.031?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.044?
Question ID: 0361392014
Looking at a collection of antique coins, \(20\%\) are made of silver. A simple random sample of \(2,200\) coins is taken.
Let \(X\) denote the number of coins sampled that are made of silver.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.207?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.201?
Question ID: 0156495232
Examining a batch of manufactured widgets, \(10\%\) are found to be defective. A simple random sample of \(3,600\) widgets is taken.
Let \(X\) denote the number of widgets sampled that are found to be defective.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.093?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.09?
Question ID: 0894684764
Within a colony of honeybees, \(8\%\) are observed performing waggle dances. A simple random sample of \(4,600\) bees is taken.
Let \(X\) denote the number of bees sampled that are observed performing waggle dances.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.09?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.083?
Question ID: 0251370473
Examining a batch of manufactured widgets, \(14\%\) are found to be defective. A simple random sample of \(2,600\) widgets is taken.
Let \(X\) denote the number of widgets sampled that are found to be defective.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.126?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.155?
Question ID: 0319663412
Looking at a collection of antique coins, \(8\%\) are made of silver. A simple random sample of \(3,100\) coins is taken.
Let \(X\) denote the number of coins sampled that are made of silver.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.087?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.068?
Question ID: 0961503892
Among patients visiting a doctor’s office, \(34\%\) report experiencing seasonal allergies. A simple random sample of \(2,500\) patients is taken.
Let \(X\) denote the number of patients sampled who report experiencing seasonal allergies.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.358?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.347?
Question ID: 0303512573
In a population of wild deer, \(16\%\) carry a specific genetic marker. A simple random sample of \(4,500\) deer is taken.
Let \(X\) denote the number of deer sampled that carry a specific genetic marker.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.152?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.146?
Question ID: 0845364135
Considering a group of surveyed households, \(18\%\) own more than one vehicle. A simple random sample of \(2,000\) households is taken.
Let \(X\) denote the number of households sampled that own more than one vehicle.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.175?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.181?
Question ID: 0058725366
Considering a group of surveyed households, \(23\%\) own more than one vehicle. A simple random sample of \(2,100\) households is taken.
Let \(X\) denote the number of households sampled that own more than one vehicle.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.239?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.229?
Question ID: 0707448540
In a population of wild deer, \(23\%\) carry a specific genetic marker. A simple random sample of \(3,700\) deer is taken.
Let \(X\) denote the number of deer sampled that carry a specific genetic marker.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.225?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.235?
Question ID: 0950496517
Among patients visiting a doctor’s office, \(20\%\) report experiencing seasonal allergies. A simple random sample of \(3,800\) patients is taken.
Let \(X\) denote the number of patients sampled who report experiencing seasonal allergies.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.19?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.212?
Question ID: 0690552118
Within a flock of migratory birds, \(42\%\) have been fitted with tracking devices. A simple random sample of \(3,900\) birds is taken.
Let \(X\) denote the number of birds sampled that have been fitted with tracking devices.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.438?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.41?
Question ID: 0148377977
Examining a batch of manufactured widgets, \(11\%\) are found to be defective. A simple random sample of \(1,800\) widgets is taken.
Let \(X\) denote the number of widgets sampled that are found to be defective.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.107?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.111?
Question ID: 0849960450
In a forest of mature oak trees, \(29\%\) show signs of a particular fungal infection. A simple random sample of \(3,500\) trees is taken.
Let \(X\) denote the number of trees sampled that show signs of a particular fungal infection.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.307?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.272?
Question ID: 0470634294
Among adults in a large city, \(29\%\) attended university. A simple random sample of \(3,300\) adults is taken.
Let \(X\) denote the number of adults sampled who attended university.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.287?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.303?
Question ID: 0045907888
Among adults in a large city, \(17\%\) attended university. A simple random sample of \(3,200\) adults is taken.
Let \(X\) denote the number of adults sampled who attended university.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.163?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.162?
Question ID: 0691449497
In a forest of mature oak trees, \(27\%\) show signs of a particular fungal infection. A simple random sample of \(1,000\) trees is taken.
Let \(X\) denote the number of trees sampled that show signs of a particular fungal infection.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.297?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.303?
Question ID: 0414431120
Considering a group of surveyed households, \(21\%\) own more than one vehicle. A simple random sample of \(2,700\) households is taken.
Let \(X\) denote the number of households sampled that own more than one vehicle.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.196?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.201?
Question ID: 0414118654
Among patients visiting a doctor’s office, \(5\%\) report experiencing seasonal allergies. A simple random sample of \(2,700\) patients is taken.
Let \(X\) denote the number of patients sampled who report experiencing seasonal allergies.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.058?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.056?
Question ID: 0880145095
Among registered voters in a province, \(47\%\) intend to vote in the upcoming election. A simple random sample of \(1,900\) voters is taken.
Let \(X\) denote the number of voters sampled who intend to vote in the upcoming election.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.488?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.488?
Question ID: 0993320602
Among adults in a large city, \(38\%\) attended university. A simple random sample of \(2,600\) adults is taken.
Let \(X\) denote the number of adults sampled who attended university.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.361?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.386?
Question ID: 0154134775
Among patients visiting a doctor’s office, \(34\%\) report experiencing seasonal allergies. A simple random sample of \(3,500\) patients is taken.
Let \(X\) denote the number of patients sampled who report experiencing seasonal allergies.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.334?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.346?
Question ID: 0172342647
In a forest of mature oak trees, \(40\%\) show signs of a particular fungal infection. A simple random sample of \(4,100\) trees is taken.
Let \(X\) denote the number of trees sampled that show signs of a particular fungal infection.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.404?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.417?
Question ID: 0719808329
Looking at a collection of antique coins, \(2\%\) are made of silver. A simple random sample of \(2,900\) coins is taken.
Let \(X\) denote the number of coins sampled that are made of silver.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.024?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.015?
Question ID: 0243018951
In a population of wild deer, \(20\%\) carry a specific genetic marker. A simple random sample of \(2,800\) deer is taken.
Let \(X\) denote the number of deer sampled that carry a specific genetic marker.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.205?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.201?
Question ID: 0205856582
Examining a batch of manufactured widgets, \(10\%\) are found to be defective. A simple random sample of \(3,300\) widgets is taken.
Let \(X\) denote the number of widgets sampled that are found to be defective.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.098?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.088?
Question ID: 0576529638
In a sample of soil from a farm, \(11\%\) contains a specific type of bacteria. A simple random sample of \(2,300\) units of soil is taken.
Let \(X\) denote the number of units of soil sampled that contains a specific type of bacteria.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.123?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.095?
Question ID: 0764487173
Within a colony of honeybees, \(10\%\) are observed performing waggle dances. A simple random sample of \(4,100\) bees is taken.
Let \(X\) denote the number of bees sampled that are observed performing waggle dances.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.096?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.107?
Question ID: 0868261120
Among patients visiting a doctor’s office, \(39\%\) report experiencing seasonal allergies. A simple random sample of \(3,000\) patients is taken.
Let \(X\) denote the number of patients sampled who report experiencing seasonal allergies.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.41?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.405?
Question ID: 0978064871
Among registered voters in a province, \(44\%\) intend to vote in the upcoming election. A simple random sample of \(2,600\) voters is taken.
Let \(X\) denote the number of voters sampled who intend to vote in the upcoming election.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.425?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.456?
Question ID: 0071367426
In a forest of mature oak trees, \(20\%\) show signs of a particular fungal infection. A simple random sample of \(3,000\) trees is taken.
Let \(X\) denote the number of trees sampled that show signs of a particular fungal infection.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.188?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.211?
Question ID: 0713481441
In a forest of mature oak trees, \(25\%\) show signs of a particular fungal infection. A simple random sample of \(3,300\) trees is taken.
Let \(X\) denote the number of trees sampled that show signs of a particular fungal infection.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.257?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.237?
Question ID: 0384694030
Among adults in a large city, \(38\%\) attended university. A simple random sample of \(2,800\) adults is taken.
Let \(X\) denote the number of adults sampled who attended university.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.358?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.364?
Question ID: 0695231498
Within a colony of honeybees, \(3\%\) are observed performing waggle dances. A simple random sample of \(3,600\) bees is taken.
Let \(X\) denote the number of bees sampled that are observed performing waggle dances.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.025?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.024?
Question ID: 0083260090
Within a flock of migratory birds, \(20\%\) have been fitted with tracking devices. A simple random sample of \(4,700\) birds is taken.
Let \(X\) denote the number of birds sampled that have been fitted with tracking devices.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.197?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.215?
Question ID: 0616048552
In a population of wild deer, \(14\%\) carry a specific genetic marker. A simple random sample of \(1,300\) deer is taken.
Let \(X\) denote the number of deer sampled that carry a specific genetic marker.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.136?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.123?
Question ID: 0966881842
Among registered voters in a province, \(37\%\) intend to vote in the upcoming election. A simple random sample of \(4,700\) voters is taken.
Let \(X\) denote the number of voters sampled who intend to vote in the upcoming election.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.378?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.376?
Question ID: 0379243033
Among adults in a large city, \(40\%\) attended university. A simple random sample of \(2,500\) adults is taken.
Let \(X\) denote the number of adults sampled who attended university.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.404?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.401?
Question ID: 0863817935
In a population of wild deer, \(9\%\) carry a specific genetic marker. A simple random sample of \(2,100\) deer is taken.
Let \(X\) denote the number of deer sampled that carry a specific genetic marker.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.098?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.089?
Question ID: 0841613229
Examining a batch of manufactured widgets, \(15\%\) are found to be defective. A simple random sample of \(1,500\) widgets is taken.
Let \(X\) denote the number of widgets sampled that are found to be defective.
- What is the expected value of the approximate sampling distribution of the sample proportion?
- What is the standard error of the sample proportion?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is less than 0.148?
- Based on the approximate sampling distribution, what is the probability that the sample proportion is greater than 0.168?
Question ID: 0157223617
Suppose that \(X\) is a random variable representing the height of an adult male, with a known mean of \(193\) and standard deviation of \(35\).
Nothing further is known about the distribution of \(X\). A sample of size 8 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0084217360
Suppose that \(X\) is a random variable representing the temperature of a liquid, with a known mean of \(40\) and standard deviation of \(2\).
Nothing further is known about the distribution of \(X\). A sample of size 7 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0603110926
Suppose that \(X\) is a random variable representing the response time of a website, with a known mean of \(935\) and standard deviation of \(24\).
It is known that \(X\) is normally distributed. A sample of size 255 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0552896730
Suppose that \(X\) is a random variable representing a soil sample’s pH level, with a known mean of \(6.62\) and standard deviation of \(1.06\).
It is known that \(X\) is normally distributed. A sample of size 179 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0361150155
Suppose that \(X\) is a random variable representing the temperature of a liquid, with a known mean of \(49\) and standard deviation of \(3\).
Nothing further is known about the distribution of \(X\). A sample of size 10 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0325112362
Suppose that \(X\) is a random variable representing the response time of a website, with a known mean of \(1343\) and standard deviation of \(10\).
It is known that \(X\) is normally distributed. A sample of size 359 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0068114135
Suppose that \(X\) is a random variable representing the time taken (in minutes) by a student to complete a quiz, with a known mean of \(50\) and standard deviation of \(2\).
Nothing further is known about the distribution of \(X\). A sample of size 122 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0619059568
Suppose that \(X\) is a random variable representing the blood pressure (systolic) of a patient, with a known mean of \(156\) and standard deviation of \(21\).
Nothing further is known about the distribution of \(X\). A sample of size 17 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0237315581
Suppose that \(X\) is a random variable representing the concentration of a chemical pollutant in a water sample, with a known mean of \(4.23\) and standard deviation of \(0.42\).
Nothing further is known about the distribution of \(X\). A sample of size 23 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0358164831
Suppose that \(X\) is a random variable representing the birthweight of an infant at a neonatal ICU, with a known mean of \(4825\) and standard deviation of \(576\).
Nothing further is known about the distribution of \(X\). A sample of size 25 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0150626303
Suppose that \(X\) is a random variable representing a soil sample’s pH level, with a known mean of \(7.46\) and standard deviation of \(0.63\).
Nothing further is known about the distribution of \(X\). A sample of size 345 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0031368202
Suppose that \(X\) is a random variable representing a soil sample’s pH level, with a known mean of \(7.22\) and standard deviation of \(1.03\).
Nothing further is known about the distribution of \(X\). A sample of size 372 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0421544145
Suppose that \(X\) is a random variable representing the temperature of a liquid, with a known mean of \(74\) and standard deviation of \(4\).
Nothing further is known about the distribution of \(X\). A sample of size 57 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0256640081
Suppose that \(X\) is a random variable representing a soil sample’s pH level, with a known mean of \(7.04\) and standard deviation of \(0.27\).
Nothing further is known about the distribution of \(X\). A sample of size 25 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0854353974
Suppose that \(X\) is a random variable representing the time taken (in minutes) by a student to complete a quiz, with a known mean of \(34\) and standard deviation of \(5\).
Nothing further is known about the distribution of \(X\). A sample of size 322 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0559338704
Suppose that \(X\) is a random variable representing an individual’s monthly expenses on groceries, with a known mean of \(690\) and standard deviation of \(15\).
It is known that \(X\) is normally distributed. A sample of size 42 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0987569556
Suppose that \(X\) is a random variable representing the birthweight of an infant at a neonatal ICU, with a known mean of \(3105\) and standard deviation of \(113\).
Nothing further is known about the distribution of \(X\). A sample of size 11 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0073999825
Suppose that \(X\) is a random variable representing the concentration of a chemical pollutant in a water sample, with a known mean of \(3.61\) and standard deviation of \(0.69\).
Nothing further is known about the distribution of \(X\). A sample of size 22 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0268642726
Suppose that \(X\) is a random variable representing the number of hours an individual exercises each week, with a known mean of \(26.82\) and standard deviation of \(1.08\).
It is known that \(X\) is normally distributed. A sample of size 368 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0778872041
Suppose that \(X\) is a random variable representing the response time of a website, with a known mean of \(485\) and standard deviation of \(19\).
It is known that \(X\) is normally distributed. A sample of size 104 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0685910534
Suppose that \(X\) is a random variable representing the blood pressure (systolic) of a patient, with a known mean of \(131\) and standard deviation of \(19\).
Nothing further is known about the distribution of \(X\). A sample of size 371 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0307198794
Suppose that \(X\) is a random variable representing a soil sample’s pH level, with a known mean of \(5.66\) and standard deviation of \(0.41\).
It is known that \(X\) is normally distributed. A sample of size 35 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0740306330
Suppose that \(X\) is a random variable representing the number of hours an individual exercises each week, with a known mean of \(10.65\) and standard deviation of \(0.37\).
It is known that \(X\) is normally distributed. A sample of size 131 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0104043499
Suppose that \(X\) is a random variable representing the response time of a website, with a known mean of \(835\) and standard deviation of \(28\).
Nothing further is known about the distribution of \(X\). A sample of size 159 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0479651815
Suppose that \(X\) is a random variable representing a soil sample’s pH level, with a known mean of \(5.63\) and standard deviation of \(0.36\).
Nothing further is known about the distribution of \(X\). A sample of size 161 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0944318635
Suppose that \(X\) is a random variable representing a soil sample’s pH level, with a known mean of \(3.98\) and standard deviation of \(0.46\).
It is known that \(X\) is normally distributed. A sample of size 174 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0474960071
Suppose that \(X\) is a random variable representing an individual’s monthly expenses on groceries, with a known mean of \(785\) and standard deviation of \(21\).
It is known that \(X\) is normally distributed. A sample of size 215 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0173432863
Suppose that \(X\) is a random variable representing the blood pressure (systolic) of a patient, with a known mean of \(99\) and standard deviation of \(23\).
Nothing further is known about the distribution of \(X\). A sample of size 17 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0617055454
Suppose that \(X\) is a random variable representing the concentration of a chemical pollutant in a water sample, with a known mean of \(3.88\) and standard deviation of \(0.38\).
Nothing further is known about the distribution of \(X\). A sample of size 13 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0877198281
Suppose that \(X\) is a random variable representing the response time of a website, with a known mean of \(154\) and standard deviation of \(30\).
It is known that \(X\) is normally distributed. A sample of size 172 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0525222998
Suppose that \(X\) is a random variable representing the number of hours an individual exercises each week, with a known mean of \(37.18\) and standard deviation of \(0.86\).
Nothing further is known about the distribution of \(X\). A sample of size 21 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0800062124
Suppose that \(X\) is a random variable representing the number of hours an individual exercises each week, with a known mean of \(39.61\) and standard deviation of \(1.55\).
It is known that \(X\) is normally distributed. A sample of size 385 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0902625643
Suppose that \(X\) is a random variable representing the birthweight of an infant at a neonatal ICU, with a known mean of \(3758\) and standard deviation of \(533\).
Nothing further is known about the distribution of \(X\). A sample of size 297 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0698486712
Suppose that \(X\) is a random variable representing the temperature of a liquid, with a known mean of \(34\) and standard deviation of \(1\).
Nothing further is known about the distribution of \(X\). A sample of size 20 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0254827970
Suppose that \(X\) is a random variable representing the birthweight of an infant at a neonatal ICU, with a known mean of \(3304\) and standard deviation of \(170\).
It is known that \(X\) is normally distributed. A sample of size 291 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0824464520
Suppose that \(X\) is a random variable representing the temperature of a liquid, with a known mean of \(68\) and standard deviation of \(5\).
Nothing further is known about the distribution of \(X\). A sample of size 13 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0129817022
Suppose that \(X\) is a random variable representing the blood pressure (systolic) of a patient, with a known mean of \(134\) and standard deviation of \(25\).
Nothing further is known about the distribution of \(X\). A sample of size 22 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0967466364
Suppose that \(X\) is a random variable representing the temperature of a liquid, with a known mean of \(92\) and standard deviation of \(4\).
Nothing further is known about the distribution of \(X\). A sample of size 182 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0331509945
Suppose that \(X\) is a random variable representing the number of hours an individual exercises each week, with a known mean of \(6.89\) and standard deviation of \(0.34\).
Nothing further is known about the distribution of \(X\). A sample of size 122 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0924319871
Suppose that \(X\) is a random variable representing the response time of a website, with a known mean of \(1535\) and standard deviation of \(29\).
It is known that \(X\) is normally distributed. A sample of size 207 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0878513792
Suppose that \(X\) is a random variable representing the birthweight of an infant at a neonatal ICU, with a known mean of \(4348\) and standard deviation of \(116\).
It is known that \(X\) is normally distributed. A sample of size 114 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0595423023
Suppose that \(X\) is a random variable representing the birthweight of an infant at a neonatal ICU, with a known mean of \(4030\) and standard deviation of \(155\).
Nothing further is known about the distribution of \(X\). A sample of size 11 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0577972964
Suppose that \(X\) is a random variable representing the concentration of a chemical pollutant in a water sample, with a known mean of \(2.01\) and standard deviation of \(0.78\).
It is known that \(X\) is normally distributed. A sample of size 22 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0641713692
Suppose that \(X\) is a random variable representing the concentration of a chemical pollutant in a water sample, with a known mean of \(0.18\) and standard deviation of \(0.85\).
Nothing further is known about the distribution of \(X\). A sample of size 325 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0572085757
Suppose that \(X\) is a random variable representing the blood pressure (systolic) of a patient, with a known mean of \(166\) and standard deviation of \(20\).
Nothing further is known about the distribution of \(X\). A sample of size 323 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0013716585
Suppose that \(X\) is a random variable representing the height of an adult male, with a known mean of \(157\) and standard deviation of \(45\).
Nothing further is known about the distribution of \(X\). A sample of size 262 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0237350641
Suppose that \(X\) is a random variable representing the temperature of a liquid, with a known mean of \(65\) and standard deviation of \(2\).
It is known that \(X\) is normally distributed. A sample of size 98 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0876254943
Suppose that \(X\) is a random variable representing the height of an adult male, with a known mean of \(198\) and standard deviation of \(34\).
Nothing further is known about the distribution of \(X\). A sample of size 21 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0995442969
Suppose that \(X\) is a random variable representing the temperature of a liquid, with a known mean of \(64\) and standard deviation of \(3\).
It is known that \(X\) is normally distributed. A sample of size 131 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0129012931
Suppose that \(X\) is a random variable representing the concentration of a chemical pollutant in a water sample, with a known mean of \(0.81\) and standard deviation of \(0.62\).
Nothing further is known about the distribution of \(X\). A sample of size 19 is taken.
- What is the mean of the sampling distribution of \(\overline{X}\)?
- What is the standard deviation of the sampling distribution of \(\overline{X}\)?
- What distribution is most appropriate to describe the sampling distribution of \(\overline{X}\)?
Question ID: 0401096242
Be that a mean, variance, median, maximum, or so forth.↩︎
In small populations the same general procedure still applies, however, it will often be the case that in smaller populations we have a lesser need for deep statistical methodologies. Instead, we will be able to rely on census techniques or similar.↩︎
Meaning that it generally represents the underlying population.↩︎
To see this, consider the example of the population of coloured squares. For each square in our sample, record a \(1\) if the square is black and a \(0\) otherwise. Then, the sample mean \(\overline{x}\) is computed as \(\frac{1}{n}\sum_{i=1}^n x_i\). This is equivalent to the number of \(i\) that have \(x_i = 1\) divided by the total number, or put differently, the number of squares that are black divided by the total number of squares. In this sense, the proportion of black squares is a sample mean, and the ensuing discussion applies equally well to either case.↩︎
The more variability in the population the more variability in statistics computed from the population. This should make some intuitive sense. If a population is very concentrated in values, it does not really matter what sample you take as everyone will be close to one another, and most samples will be similar. If instead, the population has a lot of variability, then the specific sample will matter a great deal, and you will expect tremendous variability sample-to-sample.↩︎
Note, some authors refer to the standard error as the standard error using the sample standard deviation instead. That is, they define the standard error of the sample mean to be \(\dfrac{s}{\sqrt{n}}\) rather than \(\dfrac{\sigma}{\sqrt{n}}\). This has the benefit of being able to be computed, but the drawback of not being the true value of the standard deviation of the statistic. In these notes we will refer to this, where relevant, as the estimated standard error, and we will view this quantity as a guess at the true standard error.↩︎
We can lower-bound the probabilities using Chebyshev’s inequality, but this is not necessarily a useful lower bound.↩︎